
Today, the project team started digging into the cluster's configuration. First up was the cluster's primary storage system.
Primary Storage System Configuration
The cluster will utilize the Dell NSS storage solution for user home directories over NFS providing. The NSS is a high density solution - using 3TB drives and the Dell MD3260, the system stores 180TB raw and 144TB of usable storage in 4U of rack space.

The storage system will take advantage of the cluster's FDR InfiniBand interconnect network, supporting peak write performance just above 1 GB/s and peak read performance around 1.2 GB/s. The following illustrations are sourced from a Dell whitepaper on the NSS (source: dell.com). Given these illustrations were documented a previous version of this solution, we'll do our own speed tests on our system and post them later during implementation!!
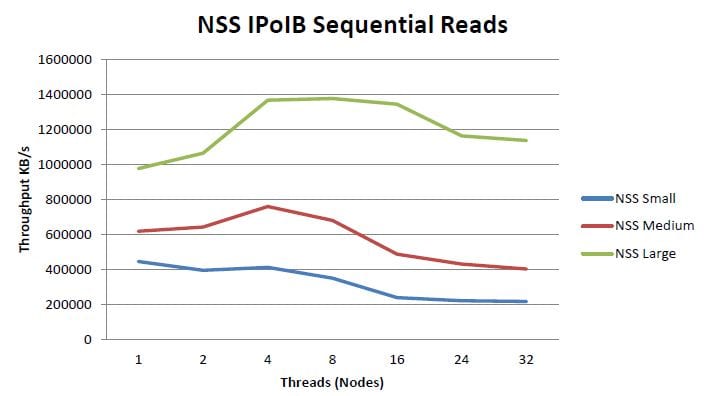
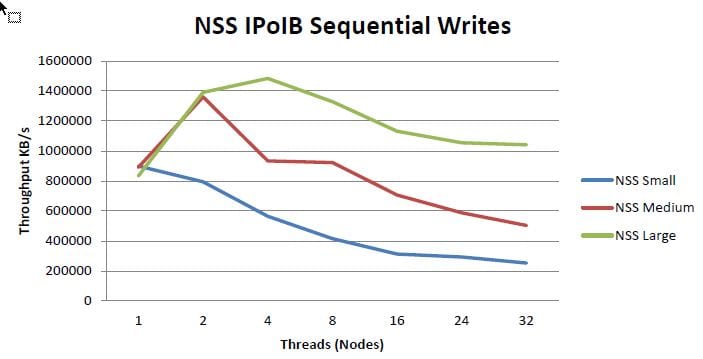
The solution is deployed in a high availability (HA) configuration with two storage controllers in an active/passive configuration. Once the base system was up and running, the team simulated a controller failure and confirmed the functionality.

The Bright software is used to provision, configure, monitor, and re-configure compute nodes throughout their lifecycle. Using a simple GUI management interface or more advanced command line interface, system administrators can easily scale node commands from a single node to all nodes in the cluster. This makes cluster management more streamlined and efficient, especially as the cluster size increases. This software will be critical in supporting users with applications that will not run on the default RedHat Enterprise Linux 6 operating system. Using Bright, non-RHEL compute node images can be built and stored for provisioning different operating systems or node configurations as necessary. Using certain advanced features and integration points between the cluster management software and job scheduler, these changes or re-provisioning tasks can be linked together for an even greater level of automation. While we can, conceptually, achieve this level of flexibility, we only want to do so on an as-needed basis to maintain consistency, availability, and supportability of the cluster.
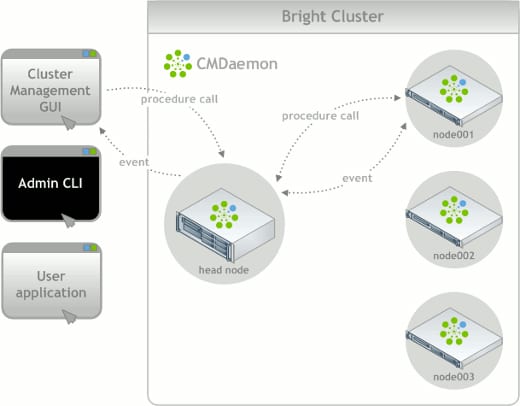
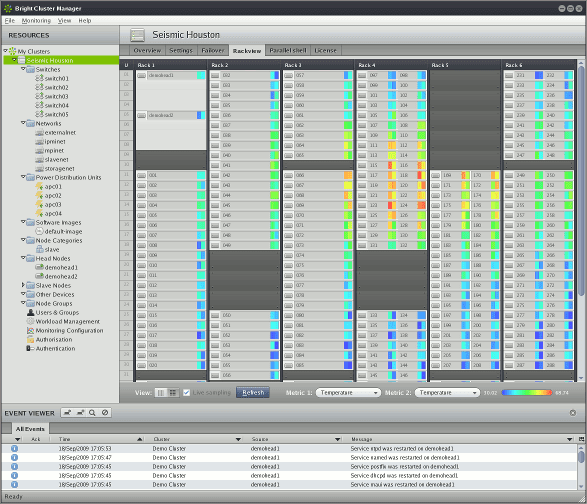
Using the built-in functionality and Bright API, there are lots of great features for integration with the job scheduler and monitoring of the cluster's hardware. There's even a visualization for multi-rack clusters using data points for cluster node health or status. Given all of the features afforded within Bright, we won't be fully utilizing the software from Day 1 - this will be a continued work in progress during the first several months.
The project team evaluated and bid several options for cluster management including open source tools, Rocks+, Bright Cluster Manager, and IBM Platform Cluster Manager. Bright was selected based on its ease of use, diverse feature set, and roadmap for extending cluster management functionality beyond on-premise clusters to cloud-based clusters. While at the annual supercomputing conference (SC12), OTS' Sean Connolly and Warren Santner had the opportunity to meet privately with the CEO of Bright Computing. This was consistent with other players in the HPC space, having their CEOs and CTOs on hand to meet with existing and potential customers. This was a very different experience compared to enterprise IT vendors! Bright's CEO, Matthijs van Leeuwen, is passionate and knowledgeable about HPC and its applications. This passion comes through loud and clear not only through the Bright product, but with everyone we've worked with from Bright thus far.
Tomorrow the team will continue configuring the cluster nodes before the on-site Terascala configuration starts on Wednesday.

















