
The Colonial One team would like to thank the people from MathWorks who came and gave us a great 2 & 1/2 hour seminar on optimizing Matlab code, porting code to C, and how to use Matlab in a distributed environment. Links to the presentation materials are here Note that the Monthly User's meeting has been postponed until January.
Category: Colonial X
First Colonial One User’s Lunch
The Colonial One Team kicked off the first Colonial One User's Lunch, 11-Oct, and was a great success! The purpose of this monthly series of meetings is to consolidate a community of users around Colonial One and give them a chance to interact and have face to face discussions with each other and the Colonial One Support Staff...a free lunch!
The lunch crowd was made up by a group of about 30 students, postdocs, and faculty with introductory discussions lead by Tim Wickberg, Warren Santner, and Glen MacLachlan.
Topics discussed included:
- An introduction to Colonial One and its hardware/software feature set.
- Getting accounts on Colonial One.
- Getting Priority Access to nodes.
- The upcoming maintenance outage (now completed).
- Colonial One Highlights
The next Colonial One User's Lunch is tentatively scheduled for the first week in November (announcements will go out) and we are always glad to see familiar faces and welcome new ones!
Here is a link to the slides shown in the meeting as well as other slide presentations.
Video Update: GW Colonial One Launch Event Video – Jun 25th, 2013
Ali Eskandarian, Dean of the College of Professional Studies and theoretical physicist, hosted this event featuring comments from Vice President Leo Chalupa, Chief Information Officer Dave Steinour, Dr. Diana Lipscomb, and Dr. Keith Crandall. The event officially launched GW's new High Performance Computing Cluster that is housed on the Virginia Science and Technology Campus of the George Washington University.
Tuesday June 25, 2013 – Colonial One Launch Event!

Today is the launch event for the Colonial One cluster! We're very excited to have Ali Eskandarian, Dean of the College of Professional Studies and theoretical physicist, host this event featuring comments from Vice President Leo Chalupa, Chief Information Officer Dave Steinour, Dr. Diana Lipscomb, and Dr. Keith Crandall.
Today's event will focus on GW's new approach to high performance research computing and feature current research in the Computational Biology Institute and the arts and sciences. Dr. Lipscomb and Dr. Crandall will discuss how Colonial One will play an integral role in supporting and expanding research at GW.
At the conclusion of the program, event attendees will have the opportunity to participate in a guided tour of the Virginia Science and Technology Campus Data Center to see the cluster and the infrastructure deployed to support it. Additionally, several faculty, students, and staff will showcase research posters demonstrating research enabled by high performance computing resources.
Event Details
Location: Enterprise Hall Executive Dining Room (2nd Floor) at the Virginia Science and Technology Campus
Time: 3PM - 5PM
Cluster Update

The initial configuration and physical deployment of the cluster was completed on May 17, 2013. When deploying complex computing clusters such as Colonial One, baseline configurations are only where the work begins. Over the past month, the project team has worked diligently with faculty in the physics and chemistry departments to benchmark, optimize, and thoroughly test the cluster. These two disciplines are important test cases as their jobs are often highly "parallelizable" with the ability to scale to a large number of nodes. Testing the cluster with these types of jobs helps to identify any configuration issues and I/O bottlenecks. The issues and optimization opportunities realized by working with these types of users will benefit all users later this year when the cluster moves into full production.
To date, we have worked with Andrei Alexandru's Physics Lattice QCD group, Hanning Chen's Theoretical and Computational Chemistry group, and Houston Miller's research group.
Lattice QCD Cluster Performance Comparison
Mike Lujan, a graduate student working in the Lattice QCD group, spent some time comparing code performance on Colonial One's NVIDIA GPU-enabled nodes with several other clusters. The Lattice QCD group's code is designed for multi-GPU and multi-CPU calculations. Due to node-to-node communication and the performance degradation when scaling a job to multiple nodes, the overall performance drops as the job uses more nodes. This is one of the reasons the GPU nodes installed in Colonial One feature dual NVIDIA KEPLER K20 GPUs, doubling the density of GPUs per node.
Here are the results of Mike's tests running single and double precision jobs:
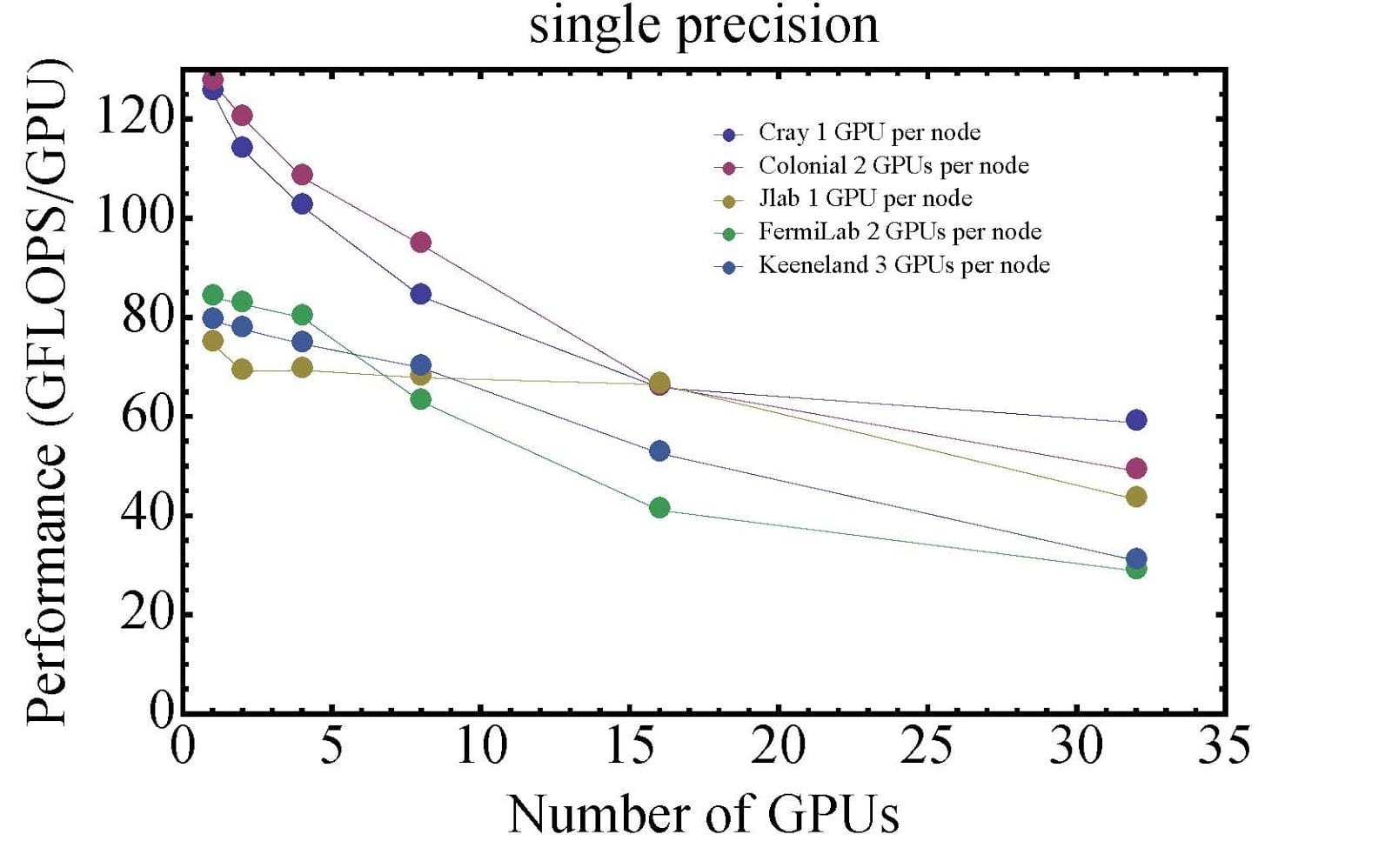
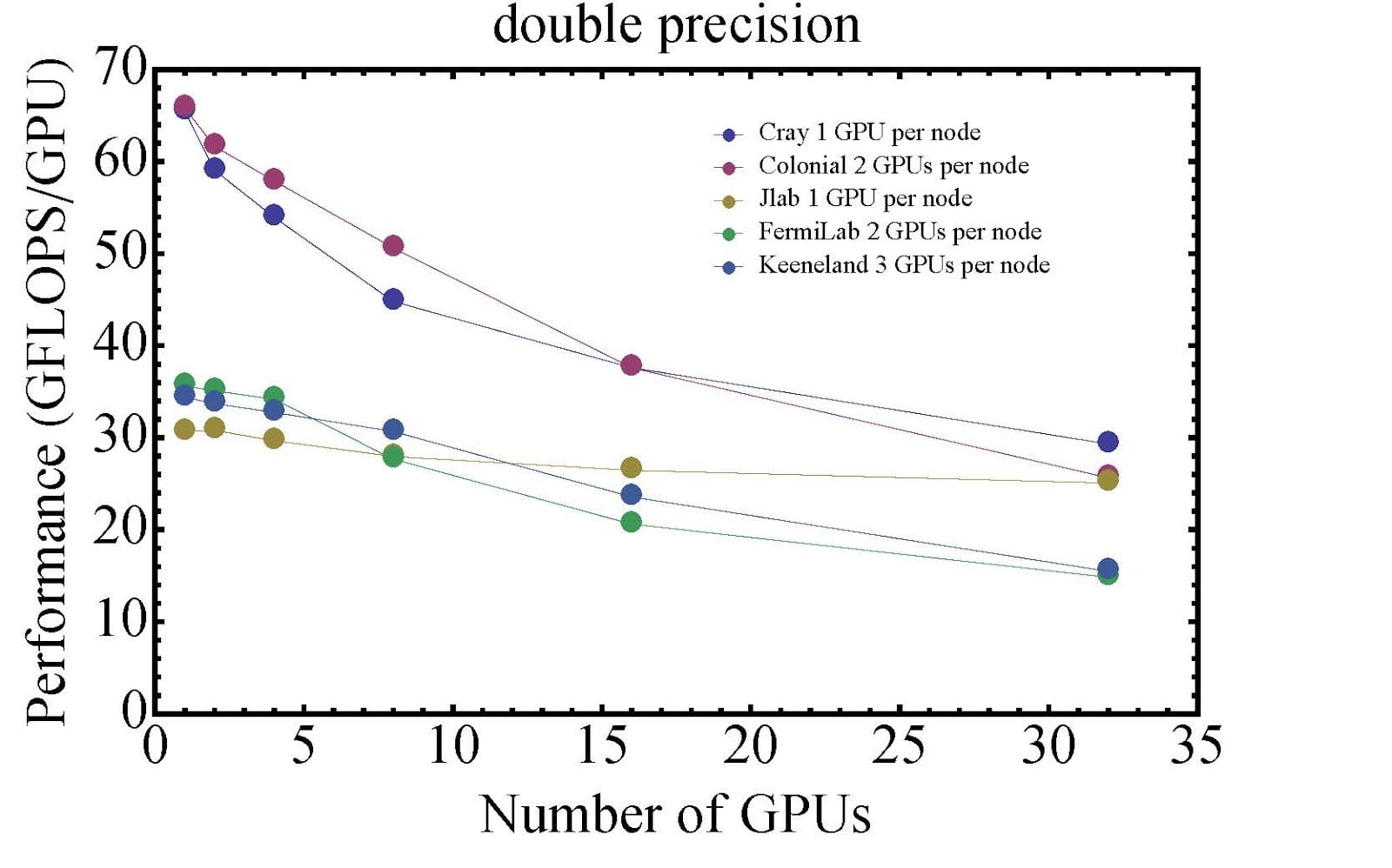
As you can see, Colonial One ranks #1 in performance up until the number of GPUs reaches 15. The Cray cluster noted is part of GW IMPACT, also known as "George." The performance gap between the top two performers and the bottom three is related to different GPU models. Both George and Colonial One are equipped with the latest GPUs from NVIDIA (K20) featuring the new Kepler architecture while the other three clusters are equipped with previous generation NVIDIA Tesla GPUs featuring the older Fermi architecture. These performance comparisons are based entirely on the code used by the Lattice QCD group, and could be higher or lower for different applications.
Special thanks to Mike for taking the time to put these performance comparisons together!
Monday May 13, 2013 – Cluster Configuration
Today, the project team started digging into the cluster's configuration. First up was the cluster's primary storage system.
Primary Storage System Configuration
The cluster will utilize the Dell NSS storage solution for user home directories over NFS providing. The NSS is a high density solution - using 3TB drives and the Dell MD3260, the system stores 180TB raw and 144TB of usable storage in 4U of rack space.

The storage system will take advantage of the cluster's FDR InfiniBand interconnect network, supporting peak write performance just above 1 GB/s and peak read performance around 1.2 GB/s. The following illustrations are sourced from a Dell whitepaper on the NSS (source: dell.com). Given these illustrations were documented a previous version of this solution, we'll do our own speed tests on our system and post them later during implementation!!
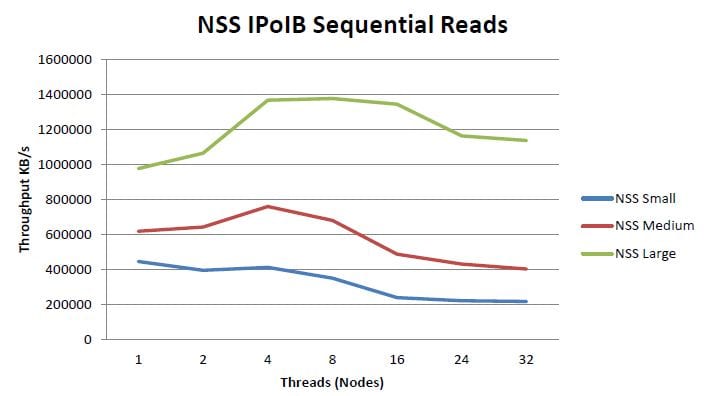
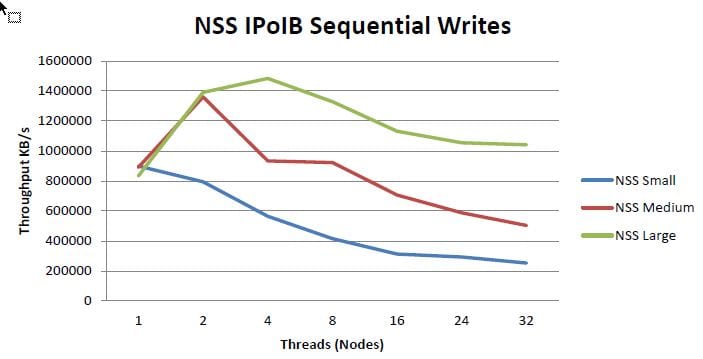
The solution is deployed in a high availability (HA) configuration with two storage controllers in an active/passive configuration. Once the base system was up and running, the team simulated a controller failure and confirmed the functionality.

Bright Cluster Management Software Deployment
In addition to deploying the primary storage system, the team installed, configured, and deployed the Bright Cluster Management software on the head nodes and compute nodes. Once the software was installed, the team pushed BIOS and firmware updates across all of the nodes.
The Bright software is used to provision, configure, monitor, and re-configure compute nodes throughout their lifecycle. Using a simple GUI management interface or more advanced command line interface, system administrators can easily scale node commands from a single node to all nodes in the cluster. This makes cluster management more streamlined and efficient, especially as the cluster size increases. This software will be critical in supporting users with applications that will not run on the default RedHat Enterprise Linux 6 operating system. Using Bright, non-RHEL compute node images can be built and stored for provisioning different operating systems or node configurations as necessary. Using certain advanced features and integration points between the cluster management software and job scheduler, these changes or re-provisioning tasks can be linked together for an even greater level of automation. While we can, conceptually, achieve this level of flexibility, we only want to do so on an as-needed basis to maintain consistency, availability, and supportability of the cluster.
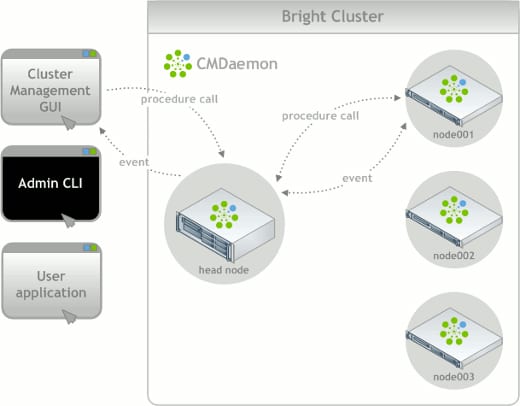
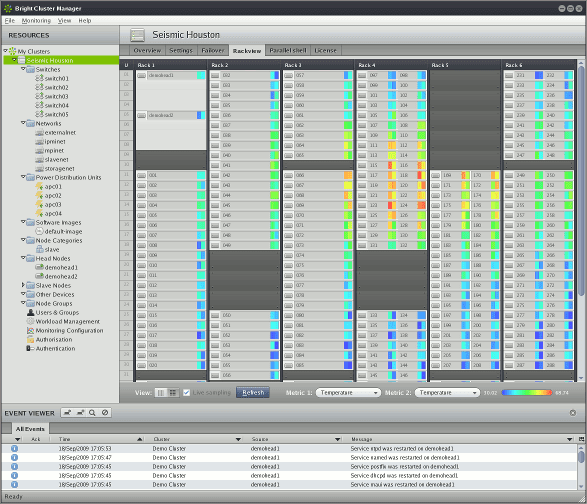
Using the built-in functionality and Bright API, there are lots of great features for integration with the job scheduler and monitoring of the cluster's hardware. There's even a visualization for multi-rack clusters using data points for cluster node health or status. Given all of the features afforded within Bright, we won't be fully utilizing the software from Day 1 - this will be a continued work in progress during the first several months.
The project team evaluated and bid several options for cluster management including open source tools, Rocks+, Bright Cluster Manager, and IBM Platform Cluster Manager. Bright was selected based on its ease of use, diverse feature set, and roadmap for extending cluster management functionality beyond on-premise clusters to cloud-based clusters. While at the annual supercomputing conference (SC12), OTS' Sean Connolly and Warren Santner had the opportunity to meet privately with the CEO of Bright Computing. This was consistent with other players in the HPC space, having their CEOs and CTOs on hand to meet with existing and potential customers. This was a very different experience compared to enterprise IT vendors! Bright's CEO, Matthijs van Leeuwen, is passionate and knowledgeable about HPC and its applications. This passion comes through loud and clear not only through the Bright product, but with everyone we've worked with from Bright thus far.
Tomorrow the team will continue configuring the cluster nodes before the on-site Terascala configuration starts on Wednesday.
Thursday May 9, 2013 – Hardware Deployment Wrap-Up
With the majority of physical deployment complete, Thursday was the final push to tie up loose ends and finalize the network cable runs. The last remaining task was running the optical InfiniBand cables between the compute racks and the InfiniBand network core. The cluster is ready for configuration on Monday morning!


Video Update: May 9, 2013 Timelapse All Cameras
Video Update: May 8, 2013 Timelapse All Cameras
Wednesday May 8, 2013 – Cabling and Labeling
With all of the hardware physically installed, the team turned its focus to installing the Ethernet and InfiniBand cables for each cluster node. Each node is connected to a 1Gbps Ethernet Management Network for administrative functions such as operating system deployment, application deployment, and certain management commands. The primary communication method for each node is the InfiniBand Interconnect Network. Each node has one 56Gbps FDR InfiniBand connection used for inter-node communication and input/output for the storage systems .


The project team focused on the most effective cable management method to ensure proper airflow to the front of the Dell C8000 compute nodes.

The day completed with the cabling for all 96 compute nodes completed!



Tomorrow is the last day scheduled for physical hardware deployment. Plenty left to do to ensure the cluster is ready for its baseline configuration next Monday!
Tuesday May 7, 2013 – Hardware Installation and Power-On Tests
Today, physical installation of the server hardware continued. With all of the 16 blade enclosures and 96 compute nodes installed yesterday, the team focused on installing the cluster's 4 head nodes, Dell NSS primary storage system, and the Dell HSS Terascala Lustre scratch storage system.

The cluster's head nodes will primarily handle user logins, cluster management, resource scheduling, data transfers in and out, and interconnect network fabric management. Each head node is equipped with dual Intel Xeon E5-2670 2.6 GHz 8-core processors, 64GB of RAM, one non-blocking 56GBps FDR InfiniBand connection to the cluster's internal interconnect network, and two 10Gb fiber uplinks to the campus network core. Combined, the head nodes will have 80 Gbps of throughput to the GW network core! With this level of data throughput into the core, researchers will be poised to take advantage of GW's robust connectivity to the public Internet, the Internet2 research institution network, and the 100Gb inter-campus link planned for later this year.

As the storage systems are physically installed, the Dell COSIP team verifies each of the 96 compute nodes by individually powering and testing each node.

The cluster's primary storage system, Dell's NSS NFS storage solution, resides in Rack #4 and features non-blocking connectivity to the cluster's high-speed FDR Infiniband interconnect network and approximately 144TB of usable capacity. There's plenty of room to expand the storage system - each additional 4U storage chassis adds 144TB of usable capacity in a simple and highly cost effective manner.

After completing the storage system installation in Rack #4, the installers focused on the installation of the Dell Terascala HSS Lustre scratch storage system. The HSS solution will provide a high-speed parallel file system to support multi-node jobs efficiently and effectively. In its current configuration, the solution supports up to 6.2 GB/s of read performance and 4.2 GB/s write performance. Both the storage capacity and performance can be expanded relatively easily by adding storage enclosures and additional object storage server (OSS) pairs.

With all of the major hardware installed, the Dell Team turns to installing, labeling, and managing cables. With 192 InfiniBand and Ethernet cables coming from the 96 compute nodes, this is no small task. Because of the amount of heat produced by the compute nodes, airflow is essential. Proper cable management will aid in establishing proper airflow for each cluster component.

Day two of the installation wrapped up around 6:30 PM. Great progress has been made in the physical deployment. Tomorrow the team will focus on running cables for the management and interconnect networks.



